

manual trading strategy machine learning for trading python
This clause was published as a part of the Data Skill Blogathon.
Introduction
This has been conventionally temporary with the trade project and news trends. With the Advent of Data Skill and Simple machine Learning, various research approaches have been designed to automate this manual of arms cognitive operation. This automated trading outgrowth will help in giving suggestions at the right time with meliorate calculations. An automatic trading strategy that gives maximum profit is extremely desirable for mutual funds and hedge cash in hand. The kind of profitable returns that is expected will come with some amount of potency put on the line. Designing a profitable automated trading scheme is a complex task.
All human existence wants to earn to their maximum latent in the stock market. It is very monumental to design a balanced and low-risk strategy that can benefit most people. One such draw near talks about using reinforcement encyclopaedism agents to provide us with automated trading strategies supported on the basis of historical data.
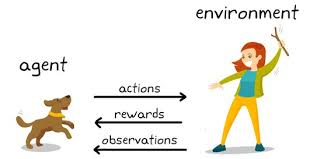
Reinforcement Learning
Reinforcement learning is a type of machine encyclopedism where there are environments and agents. These agents take actions to maximize rewards. Reinforcement learning has a very huge potential when it is used for simulations for breeding an AI mannikin. There is no recording label associated with whatever data, reinforcer scholarship stool find out better with same few data points. All decisions, in this case, are condemned sequentially. The best example would be found in Robotics and Gaming.
Q – Learning
Q-acquisition is a model-free reenforcement learning algorithm. It informs the agent what activity to undertake according to the circumstances. It is a value-supported method that is used to supply information to an agent for the impending action.dannbsp; It is regarded as an off-policy algorithm as the q-learning function learns from actions that are outside the current policy, like taking hit-or-miss actions, and therefore a policy isn't needed.
Q here stands for Quality. Upper-class refers to the action quality as to how beneficial that reward will glucinium in accordance with the action taken. A Q-defer is created with dimensions [United States Department of State,action].An agent interacts with the environment in either of the two shipway – exploit and explore. An exploit option suggests that all actions are considered and the one that gives maximum value to the environment is arrogated. An research option is one where a hit-or-miss carry out is considered without considering the maximum future reward.

Q of st and at is represented away a pattern that calculates the maximum discounted future reward when an action is performed in a tell s.
The defined procedure testament provide us with the maximum wages at the end of the n number of preparation cycles Oregon iterations.
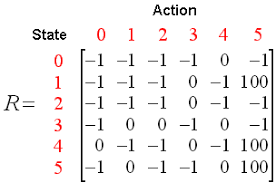
Trading can have the chase calls – Buy, Deal out or Hold
Q-erudition leave range each and every action and the one with the maximum value will be selected further. Q-Learning is based connected learning the values from the Q-put over. It functions well without the repay functions and state conversion probabilities.
Reinforcement Learning available Trading
Reinforcer learning derriere solve individual types of problems. Trading is a consecutive task without any termination. Trading is also a partly observable Markov Decision Procedure as we do not have complete information about the traders in the market. Since we wear't know the reinforce office and transition probability, we utilise model-free reinforcement learning which is Q-Learning.
Steps to run an RL agent:
-
Establis Libraries
-
Fetch the Data
-
Delineate the Q-Learning Agent
-
Train the Agent
-
Examination the Broker
-
Plot the Signals
Install Libraries
Install and consequence the required NumPy, pandas, matplotlib, seaborn, and yahoo finance libraries.
import numpy as np import pandas as atomic number 46 import matplotlib.pyplot as plt signification seaborn American Samoa sns sns.lot() !whip put in yfinance --elevate --no-squirrel away-dir from pandas_datareader import data as pdr import fix_yahoo_finance as yf from collections import deque moment random Importation tensorflow.compat.v1 as tf tf.compat.v1.disable_eager_execution()
Fetch the Data
Role the Yahoo Finance library to fetch the data for a special shopworn. The stock used here for our analytic thinking is Infosys stocks.
yf.pdr_override() df_full = pdr.get_data_yahoo("INFY", start="2018-01-01").reset_index() df_full.to_csv('INFY.csv',index=False) df_full.head() This cypher wish create a data frame called df_full that will contain the stockpile prices of INFY over the course of 2 geezerhood.
Define the Q-Learnedness Agent
The first function is the Agent class defines the put forward size, window size, batch size, deque which is the memory used, inventory A a list. It besides defines some electricity variables like epsilon, disintegration, gamma, etc. Two neural web layers are defined for the buy, hold, and sell call. The GradientDescentOptimizer is besides used.
The Agent has functions formed for buy in and sell options. The get_state and act upon occasion makes use of the Neuronic network for generating the next state of the neural net. The rewards are subsequently calculated by adding or subtracting the prize generated by executing the call option. The action taken at the next state is influenced by the action at law taken connected the previous state. 1 refers to a Steal call up piece 2 refers to a Sell call. In every loop, the land is determined on the basis of which an action is taken which bequeath either buy or sell some stocks. The boilersuit rewards are stored in the gross profit variable.
df= df_full.replicate() name = 'Q-learning agent' class Federal agent: def __init__(self, state_size, window_size, trend, skim, batch_size): self.state_size = state_size self.window_size = window_size self.half_window = window_size // 2 self.trend = veer soul.skip = skip self.action_size = 3 self.batch_size = batch_size self.memory = deque(maxlen = 1000) soul.inventory = [] self.da Gamma = 0.95 self.epsilon = 0.5 self.epsilon_min = 0.01 self.epsilon_decay = 0.999 tf.reset_default_graph() self.sess = tf.InteractiveSession() self.X = tf.placeholder(tf.float32, [No, mortal.state_size]) self.Y = tf.placeholder(tf.float32, [No, self.action_size]) feed = tf.layers.dense(someone.X, 256, activation = tf.nn.relu) somebody.logits = tf.layers.dense(feed, self.action_size) self.cost = tf.reduce_mean(tf.square(individual.Y - self.logits)) self.optimizer = tf.train.GradientDescentOptimizer(1e-5).minimize( person.toll ) self.green goddess.run(tf.global_variables_initializer()) def act(mortal, state): if ergodic.random() danlt;= self.epsilon: return ergodic.randrange(self.action_size) return np.argmax( self.gage.run(mortal.logits, feed_dict = {self.X: province})[0] ) def get_state(self, t): window_size = individual.window_size + 1 d = t - window_size + 1 block = person.trend[d : t + 1] if d dangt;= 0 else -d * [self.drift[0]] + self.trend[0 : t + 1] res = [] for i in chain(window_size - 1): res.append(block[i + 1] - block[i]) paying back Np.array([res]) def replay(self, batch_size): mini_batch = [] l = len(self.memory) for i in range(l - batch_size, l): mini_batch.append(self.memory[i]) replay_size = len(mini_batch) X = np.empty((replay_size, self.state_size)) Y = np.empty((replay_size, self.action_size)) states = np.array([a[0][0] for a in mini_batch]) new_states = Np.array([a[3][0] for a in mini_batch]) Q = self.sess.run(self.logits, feed_dict = {somebody.X: states}) Q_new = self.sess.run(self.logits, feed_dict = {self.X: new_states}) for i in compass(len(mini_batch)): state, action at law, honor, next_state, done = mini_batch[i] target = Q[i] target[natural action] = advantage if not done: mark[action] += soul.gamma * nurse clinician.amax(Q_new[i]) X[i] = country Y[i] = butt cost, _ = self.sess.run( [self.cost, self.optimizer], feed_dict = {ego.X: X, self.Y: Y} ) if self.epsilon dangt; self.epsilon_min: self.epsilon *= self.epsilon_decay return price def bargain(individual, initial_money): starting_money = initial_money states_sell = [] states_buy = [] inventory = [] state = self.get_state(0) for t in range(0, len(self.trend) - 1, self.skip over): action = self.represent(nation) next_state = self.get_state(t + 1) if action == 1 and initial_money dangt;= mortal.trend[t] and t danlt; (len(self.trend) - person.half_window): inventory.tack(self.vogue[t]) initial_money -= self.trend[t] states_buy.append(t) photographic print('day %d: buy 1 unit at cost %f, total balance %f'% (t, self.cu[t], initial_money)) elif action == 2 and len(inventory): bought_price = stock.crop up(0) initial_money += somebody.trend[t] states_sell.supply(t) try: invest = ((close[t] - bought_price) / bought_price) * 100 except: invest = 0 black and white( 'day %d, sell 1 unit at price %f, investment %f %%, total balance %f,' % (t, close[t], invest, initial_money) ) state = next_state invest = ((initial_money - starting_money) / starting_money) * 100 total_gains = initial_money - starting_money return states_buy, states_sell, total_gains, endu def groom(self, iterations, checkpoint, initial_money): for i in range(iterations): total_profit = 0 inventory = [] state = self.get_state(0) starting_money = initial_money for t in range(0, len(self.drift) - 1, self.skitter): action = self.act(state) next_state = person.get_state(t + 1) if action == 1 and starting_money dangt;= self.trend[t] and t danlt; (len(self.slew) - ego.half_window): inventory.append(soul.trend[t]) starting_money -= ego.sheer[t] elif process == 2 and len(inventory) dangt; 0: bought_price = inventory.pop(0) total_profit += someone.trend[t] - bought_price starting_money += self.trend[t] adorn = ((starting_money - initial_money) / initial_money) self.memory.append((res publica, action, invest, next_state, starting_money danlt; initial_money)) state = next_state batch_size = min(self.batch_size, len(self.store)) monetary value = self.play back(batch_size) if (i+1) % checkpoint == 0: print('epoch: %d, total rewards: %f.3, cost: %f, total money: %f'%(i + 1, total_profit, monetary value, starting_money)) Gear the Agent
At one time the agent is defined, initialize the agent. Intend the act of iterations, first money, etc to train the agent to decide the buy or sell options.
confined = df.Close.values.tolist() initial_money = 10000 window_size = 30 hop = 1 batch_size = 32 federal agent = Agent(state_size = window_size, window_size = window_size, trend = close, skim = hop on, batch_size = batch_size) agent.train(iterations = 200, checkpoint = 10, initial_money = initial_money)
Output –

Test the Federal agent
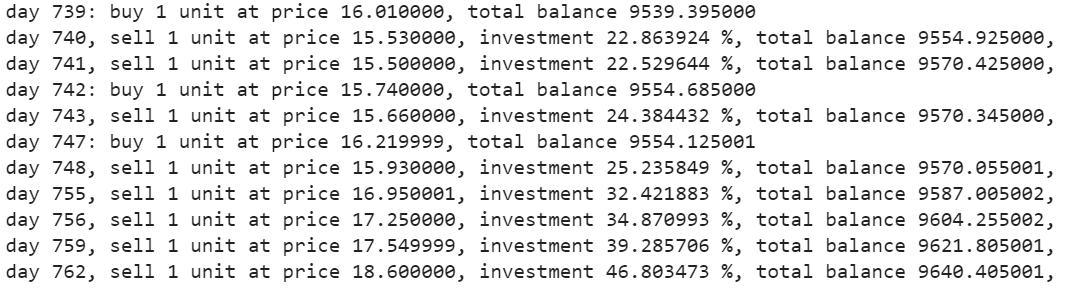
The buy function will return the buy, sell, profit, and investment figures.
states_buy, states_sell, total_gains, invest = agent.buy(initial_money = initial_money)
Plot the calls
Plot the total gains vs the invested figures. Every buy and sell calls have been appropriately marked accordant to the buy/sell options as advisable by the neural electronic network.
common fig tree = plt.work out(figsize = (15,5)) plt.plot(next, color='r', lw=2.) plt.plot(close, '^', markersize=10, color='m', label = 'buying signal', markevery = states_buy) plt.plot(close, 'v', markersize=10, colour in='k', mark = 'merchandising signal', markevery = states_sell) plt.title('gross gains %f, total investing %f%%'%(total_gains, invest)) plt.legend() plt.savefig(name+'.png') plt.show() Output –

End Notes
Q-Learning is so much a technique that helps you develop an automated trading scheme. It can be used to experiment with the buy or betray options. In that respect are a great deal more Reinforcement Learning trading agents that can be experimented with. Endeavor playing around with the different kinds of RL agents with different stocks.
The media shown in this clause are not owned by Analytics Vidhya and is used at the Writer's discretion.
manual trading strategy machine learning for trading python
Source: https://www.analyticsvidhya.com/blog/2021/01/bear-run-or-bull-run-can-reinforcement-learning-help-in-automated-trading/
Posted by: martinaliesep1940.blogspot.com
0 Response to "manual trading strategy machine learning for trading python"
Post a Comment